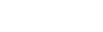
【儀表網(wǎng) 研發(fā)快訊】多模態(tài)大模型在通用任務(wù)上表現(xiàn)出色,但缺乏細(xì)粒度感知能力,如何做到又廣(開域泛化能力)又深(細(xì)粒度感知能力),是推動大模型從聊天助手到自動駕駛、具身智能、醫(yī)療影像、工業(yè)制造等實際應(yīng)用中急需解決的關(guān)鍵問題。針對上述問題,北京大學(xué)王選計算機研究所彭宇新教授團隊近期取得了一系列重要進展,包括研發(fā)并開源了首個細(xì)粒度多模態(tài)大模型Finedefics、發(fā)表首篇細(xì)粒度多模態(tài)大模型綜述論文等。相關(guān)成果發(fā)表于IEEE TPAMI、CVPR、ICLR等人工智能領(lǐng)域國際頂級期刊和會議,包括CVPR的口頭報告論文(接收率3.3%)和亮點論文(接收率13.5%)。
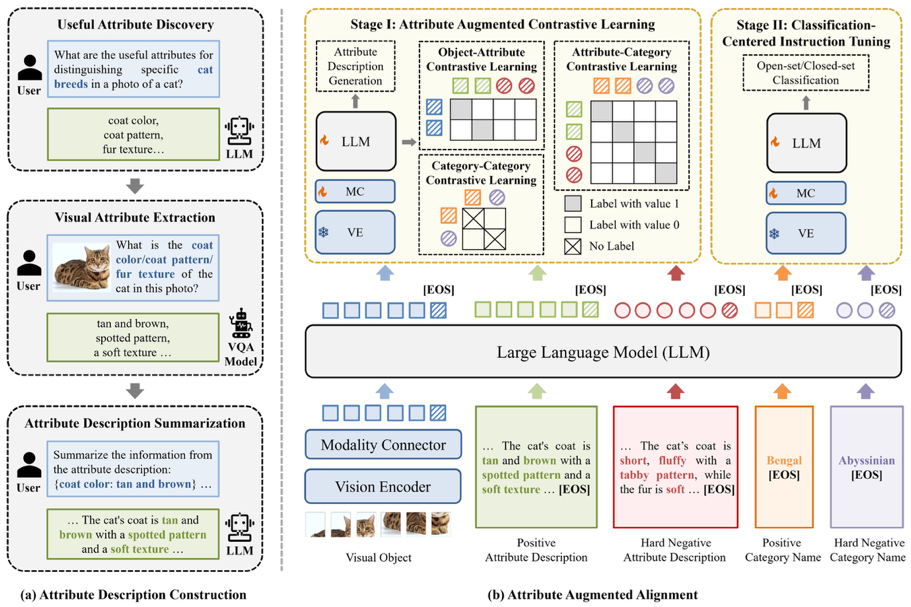
圖1. 細(xì)粒度多模態(tài)大模型Finedefics
針對現(xiàn)有大模型無法準(zhǔn)確區(qū)分細(xì)粒度類別的問題,團隊研發(fā)并開源了首個細(xì)粒度多模態(tài)大模型Finedefics,首先通過與大模型的多輪交互構(gòu)建細(xì)粒度子類別的屬性知識,然后通過判別-生成統(tǒng)一的指令微調(diào)將屬性知識分別與細(xì)粒度子類別的圖像與文本對齊,實現(xiàn)數(shù)據(jù)-知識協(xié)同訓(xùn)練,提高了多模態(tài)大模型的細(xì)粒度圖像分類能力,準(zhǔn)確率達到76.84%,相比阿里的通義千問大模型(QwenVL-Chat)提高了9.43%,相比HuggingFace的Idefics2大模型提高了10.89%。本工作發(fā)表于人工智能領(lǐng)域國際頂級會議ICLR 2025。
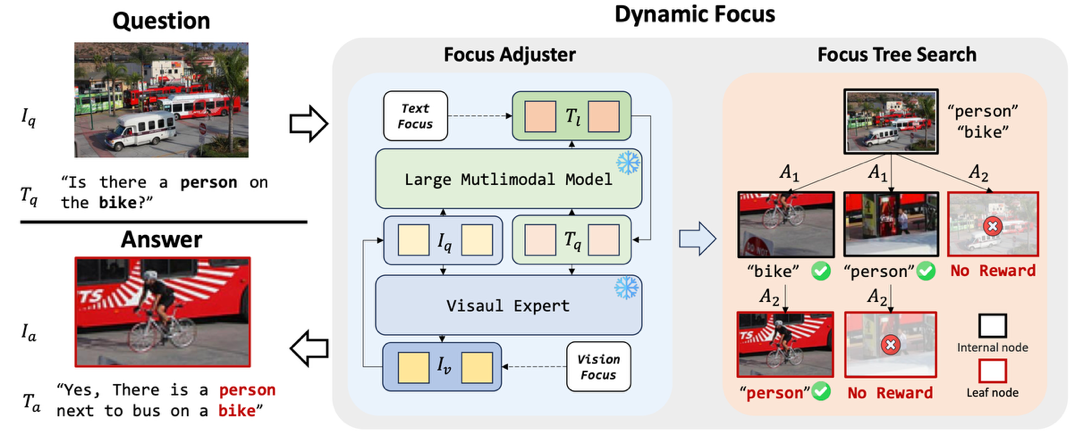
圖2. 細(xì)粒度視覺推理算法DyFo
針對現(xiàn)有大模型無法準(zhǔn)確識別圖像中微小目標(biāo)的問題,團隊提出了細(xì)粒度視覺推理算法DyFo,通過視覺專家模型與多模態(tài)大模型的協(xié)同,在無需額外訓(xùn)練的前提下,模擬人類視覺搜索行為逐步聚焦圖像關(guān)鍵區(qū)域,提高了多模態(tài)大模型的細(xì)粒度視覺識別能力,準(zhǔn)確率達到81.15%,相比阿里的通義千問大模型(Qwen2-VL)提高了8.90%。本工作發(fā)表于計算機視覺領(lǐng)域國際頂級會議CVPR 2025,入選大會亮點論文(接收率13.5%)。
圖3. 以人為中心的細(xì)粒度人體動作質(zhì)量評估方法Uni-FineParser
針對運動視頻中人體動作難以分析的問題,團隊提出了以人為中心的細(xì)粒度人體動作質(zhì)量評估方法Uni-FineParser,通過聚焦前景目標(biāo)動作區(qū)域,提取以人為中心的動作表征,然后通過細(xì)粒度對比回歸將動作過程分解為連續(xù)的動作步驟,量化每個動作步驟的質(zhì)量,綜合各步驟質(zhì)量差異預(yù)測最終動作質(zhì)量得分,動作得分的斯皮爾曼相關(guān)系數(shù)達到95.01%。本工作發(fā)表于人工智能領(lǐng)域國際頂級期刊IEEE TPAMI(影響因子18.6)。
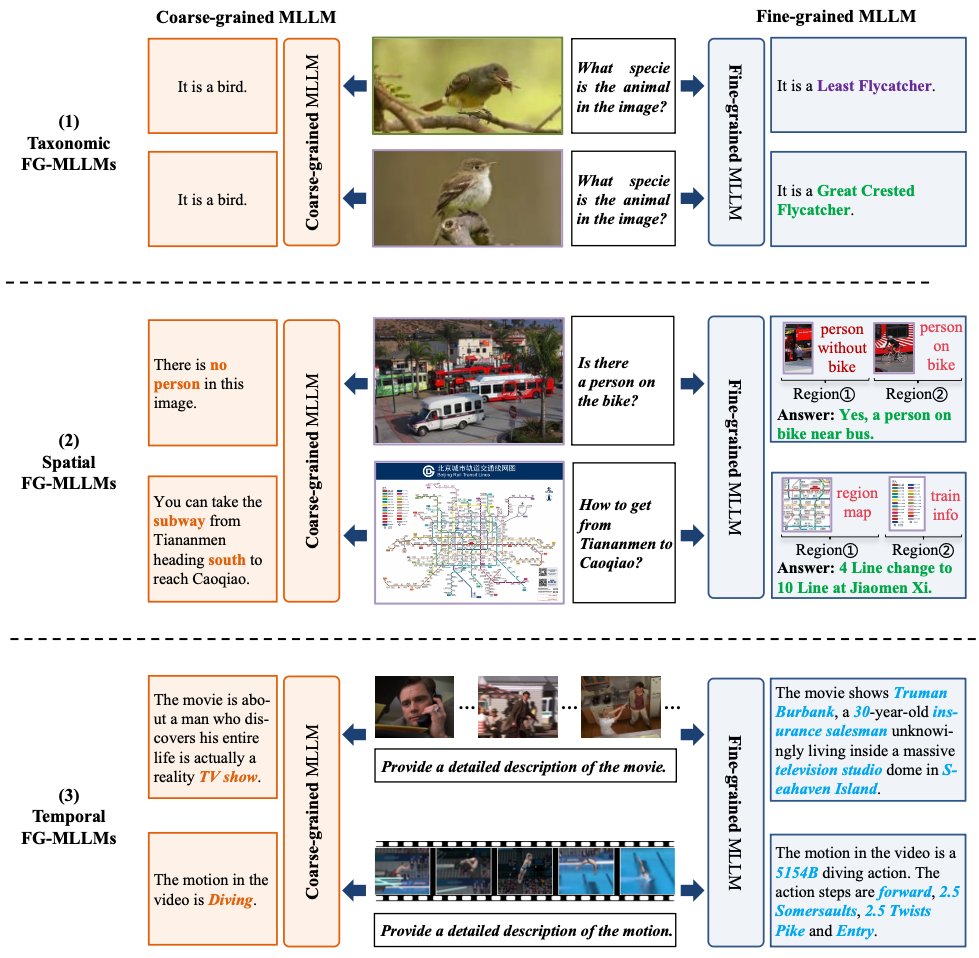
圖4. 細(xì)粒度感知定義
團隊根據(jù)在細(xì)粒度分析和多模態(tài)大模型領(lǐng)域的技術(shù)積累與前沿探索,發(fā)表了首篇細(xì)粒度多模態(tài)大模型綜述論文,剖析了當(dāng)前多模態(tài)大模型的三大挑戰(zhàn):模型架構(gòu)在細(xì)粒度特征建模上的不足;高質(zhì)量細(xì)粒度標(biāo)注數(shù)據(jù)稀缺;細(xì)粒度感知與計算效率之間的矛盾。論文從類別、空間、時間3個維度定義了細(xì)粒度感知,系統(tǒng)闡述了細(xì)粒度多模態(tài)大模型的最新研究進展,并深入探討了精度-泛化-效率權(quán)衡、知識增強策略、理解與生成統(tǒng)一、大規(guī)模評測基準(zhǔn)、細(xì)粒度多模態(tài)推理等未來發(fā)展方向。本工作發(fā)表于CJE 2026。
除上述代表論文外,團隊近期還取得了如下主要研究成果:團隊近期的4篇論文發(fā)表于人工智能領(lǐng)域國際頂級期刊IEEE TPAMI,一篇論文入選CVPR大會口頭報告(接收率3.3%),3篇論文入選CVPR大會亮點論文(接收率11.8%),兩篇論文入選2025年ESI高被引論文;構(gòu)建并開源了兩個細(xì)粒度人體運動分析數(shù)據(jù)集和評測基準(zhǔn)FineDiving-HM和FineSports,已被斯坦福大學(xué)、英偉達等60多個研究機構(gòu)使用,團隊還研發(fā)了首個在國產(chǎn)昇騰處理器上完成訓(xùn)練的生物領(lǐng)域細(xì)粒度多模態(tài)大模型,并發(fā)布到開源社區(qū);團隊研發(fā)了端側(cè)大模型輕量化、美學(xué)理解、大模型強化學(xué)習(xí)加速、電商廣告海報生成、電商短視頻生成、自動駕駛障礙物感知等系統(tǒng),應(yīng)用于華為、快手、阿里、騰訊、美團、蔚來、中國電信、中國鐵塔、中國航天科工三院等12家頭部企業(yè);參加CVPR 2025第一視角視頻檢測競賽、CVPR 2025多模態(tài)視覺問答競賽、ACM MM 2025視頻生成競賽,均獲第一名;彭宇新獲2025年青年科學(xué)基金項目A類(原國家杰青)延續(xù)資助(當(dāng)年資助期滿的杰青項目中不超過20%獲延續(xù)資助),入選2026年度IEEE Fellow、2025年度CCF會士,當(dāng)選中國圖象圖形學(xué)學(xué)會第九屆理事會副理事長,連續(xù)5年入選愛思唯爾“中國高被引學(xué)者”,主持2025年國家自然科學(xué)基金重點項目等。




















所有評論僅代表網(wǎng)友意見,與本站立場無關(guān)。